




作者 | 麦飞
编辑 | 卷毛






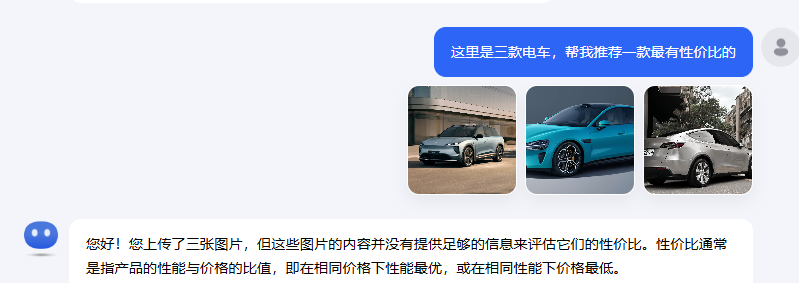
多模态对话





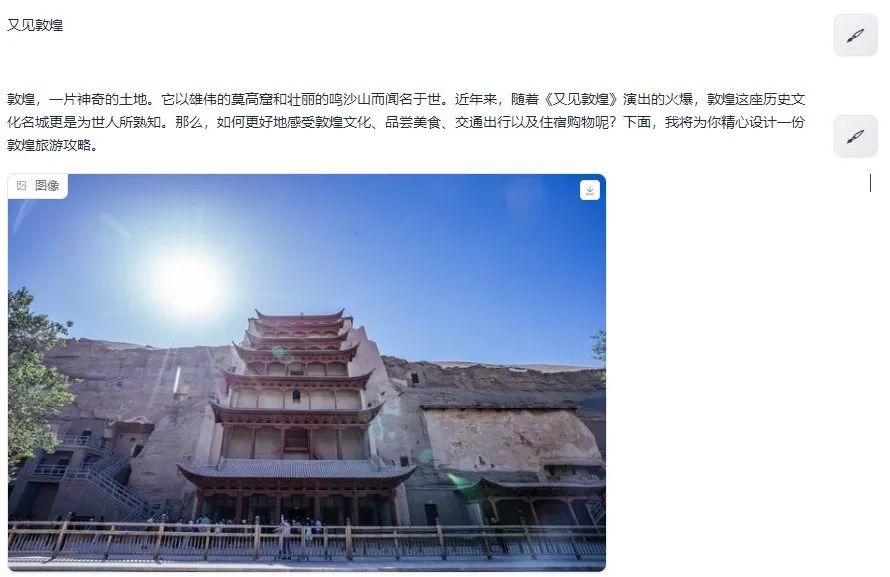
图文混合创作















书生·万象2.0:多模态大模型,和书生·浦语同样属于底座大模型,支持图像、视频、文字、语音、三维点云等模态处理。
书生·风乌:气象大模型,扩展至气象海洋全方位预报体系,覆盖海陆空多种核心要素。
书生·翼飞:航空大模型,由上海AI实验室与中国商飞上海飞机设计院(上飞院)联合推出。
书生·瞳真:光学大模型,首次实现了无需穿戴设备的超广角全视差裸眼3D成像。
直播预告
明晚18点,来视频号“头号AI玩家”直播间
看如何用AI做创意视频!





「AI新榜交流群」进群方式:添加微信“banggebangmei”并备注姓名+职业/公司+进群,欢迎玩家们来群里交流,一起探索见证AI的进化。
欢迎分享、点赞、在看
一起研究AI




